Stellenbosch Symposium on Biodiversity Informatics
22 June 2022
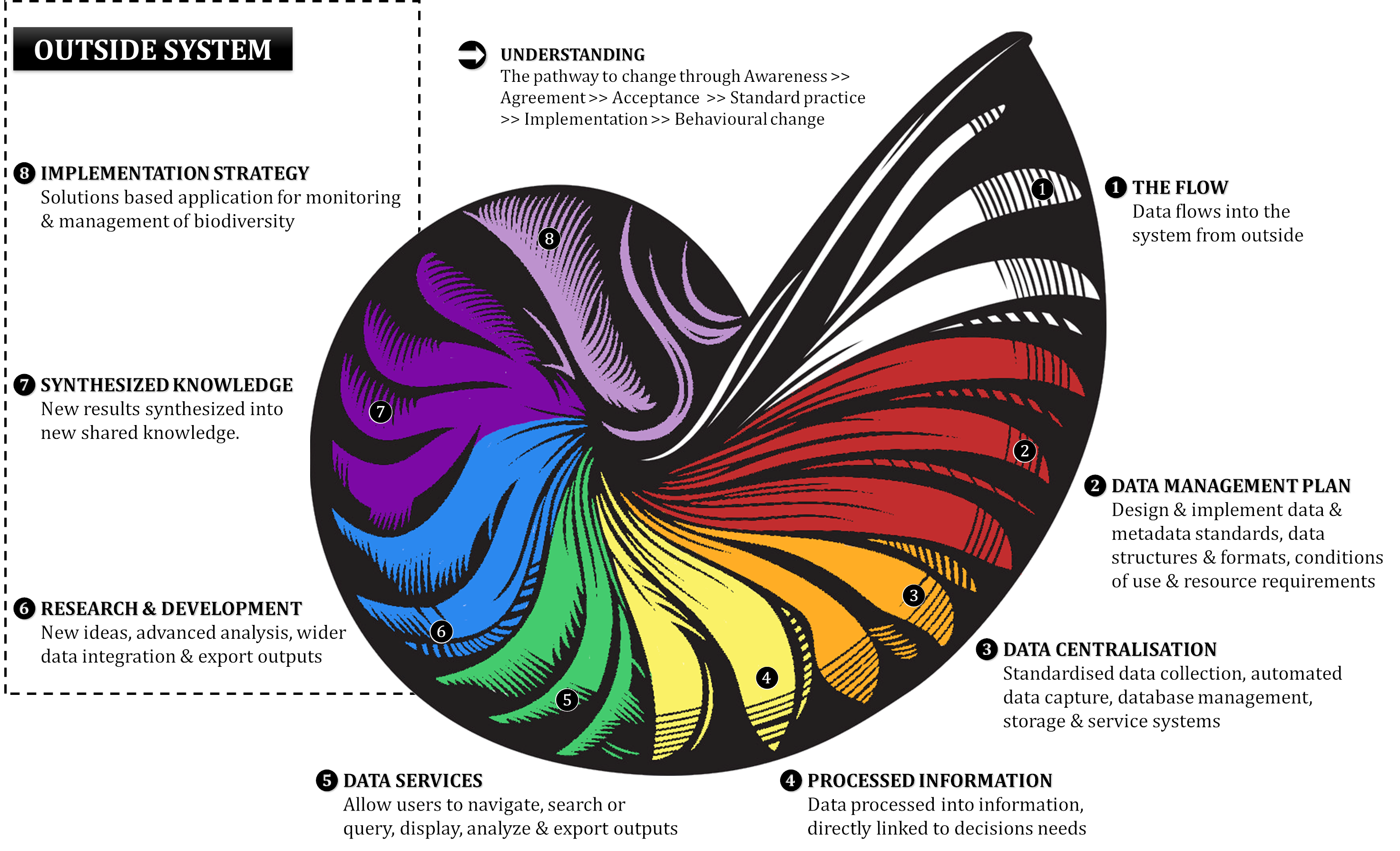
The world is drowning in data, yet thirsty for information and the synthesis of knowledge into understanding. The volume, diversity and speed at which new ecological data are generated is growing exponentially as predictions of worldwide biodiversity declines are reinforced using in situ measurements/data. Those able to successfully generate, collect, store, share, analyse and promote synthesised biodiversity data will become central players in the debate around global biodiversity change. At the same time, Africa is poised to become a world leader in biodiversity conservation, as it safeguards some of the largest wilderness areas and intact ecosystems in the world. Developing a culture of cooperation and interoperability among custodians of data to establish operational workflows for data synthesis in SA is therefore essential. To do this effectively we aim to bring together all biodiversity stakeholders and relevant expertise to encourage the establishment of transdisciplinary, collaborative networks that leverage this combined expertise from computer scientists and information technologists, librarians and historians, statisticians and mathematicians, ecologists, social scientists, local communities and conservation managers to make data readily and sensibly accessible.
For more information and to register for the symposium visit